I've been lurking around the cloud vendors' freebies for a while now, and I realized the best 'Always free' tier is neither from AWS, GCP, nor Azure ... it's from my bad boi Oracle, and it is surprisingly good. Among that is one eye-catching offer: 20GB of Oracle Autonomous JSON Database. It's based on the multi-model Oracle Database but geared towards storing JSON and performing SQL and NoSQL-style queries. Keep reading to see my experience working with it and decide if it'll be an ideal pick for your next project. ⛵
Let's get this clear, working with JSON data in relational databases isn't a new thing. MySQL and Postgres have done this for a long time. And you aren't just storing the JSON as a VARCHAR or TEXT here. It is a natively supported datatype: You can deal with queries, joins, constraints, and stuff directly on the JSON when it's natively supported, just like you do with regular relational data. This experience of using SQL queries over JSON data is quite different from pure document stores like MongoDB, where the queries are in JSON.
So what's so special about Oracle Autonomous JSON Database (AJD)? The product features might not be unique, but it is undoubtedly a solid DBaaS choice: A fully-managed cloud-hosted document store, 20GB of forever-free space, automatic daily backups, with both SQL and MongoDB-like NoSQL APIs to manage your data ... I picked it up without a second thought. You know I don't usually promote non-FOSS solutions, but hey, who doesn't want cool freebies for personal projects?
Database setup
First, you'll need an Oracle cloud account (of course, a credit card too). I won't be going into setup details for the AJD instance, but it's a matter of a few clicks when you refer to this page. Just watch out for the correct options along the way (We're setting up a JSON DB, not Transaction Processing or Warehouse DB). Once the setup ends, proceed to Database Actions (a.k.a. SQL Developer), and log in. You'll reach this screen:
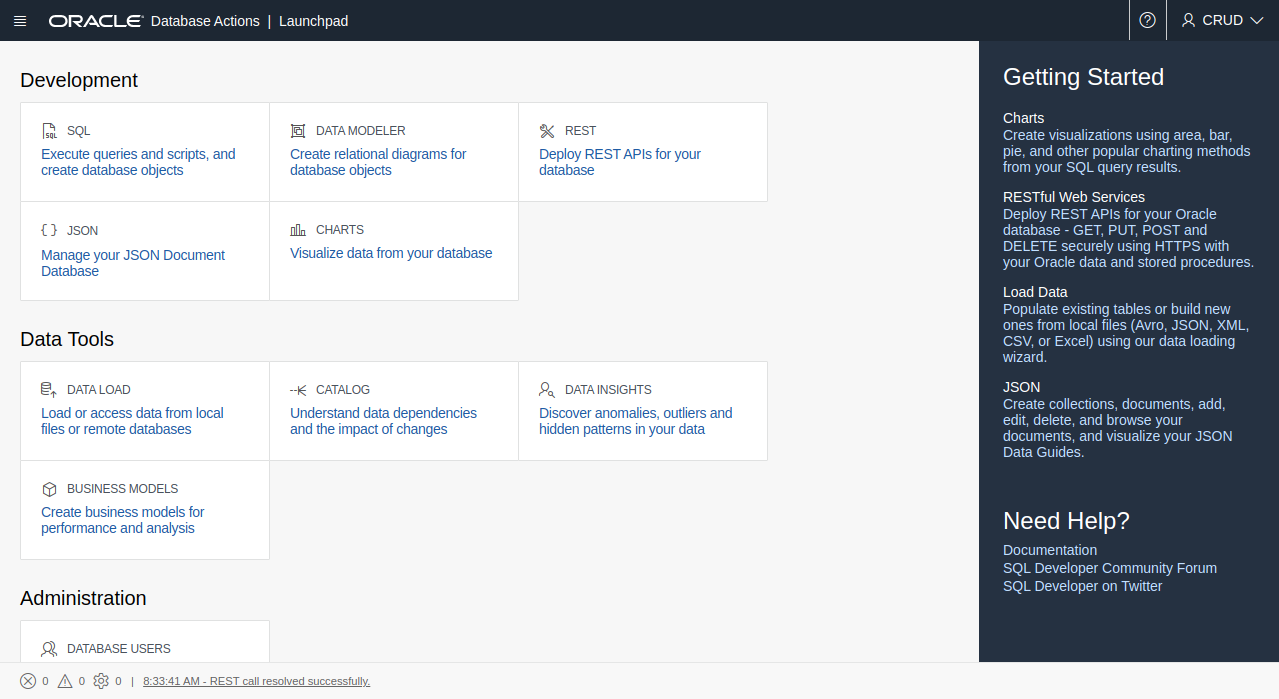
There are two particular links in the 'Development' sections: The JSON mode to work in NoSQL-style, and the SQL mode for extra customization. Start with the JSON mode, and a tutorial should greet you. I created a collection known as veggies and put three documents in there.
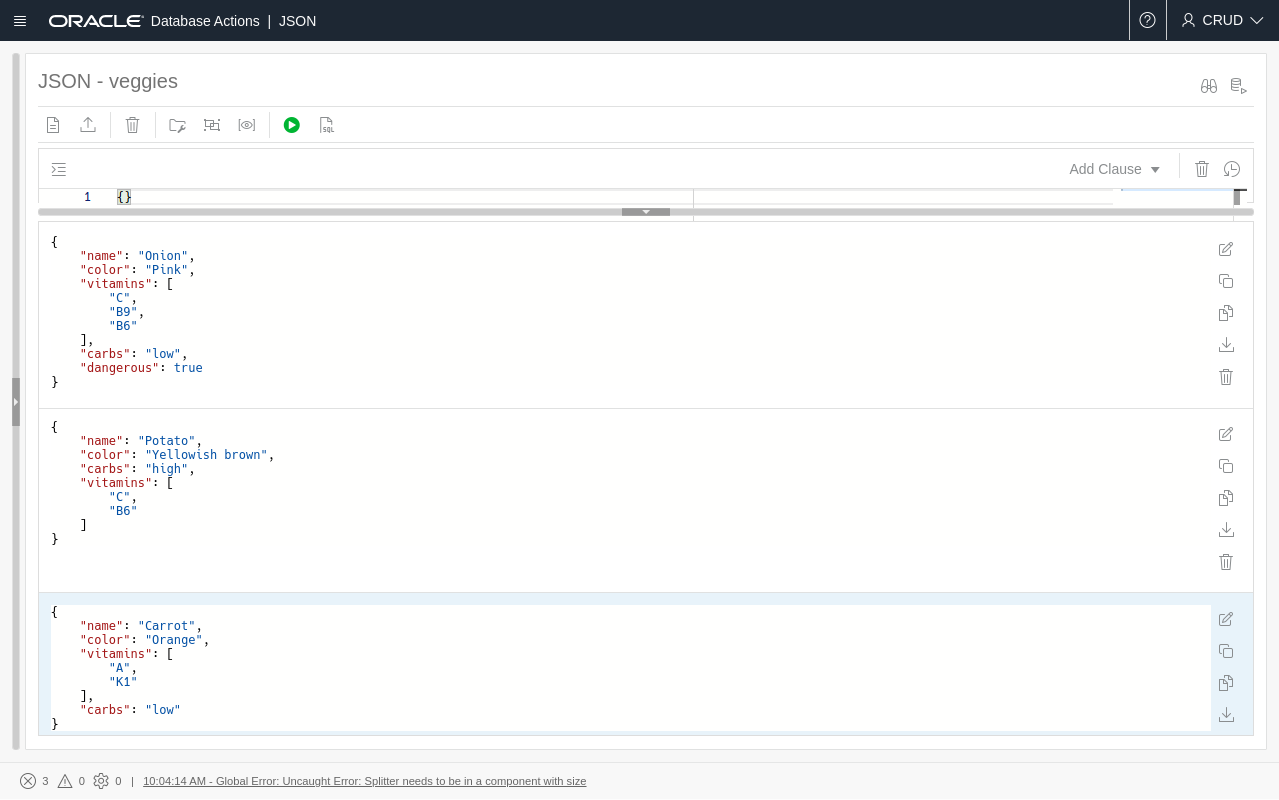
NoSQL style
Here's how we query by example (QBE): Pass in a JSON object with any key-value pair, and it will return you a list of documents having similar properties. Let's get the veggies with low carbs and vitamin C:
// Query
{"carbs": "low", "vitamins": "C"}
// Output
{
"name": "Onion",
"color": "Pink",
"vitamins": [
"C",
"B9",
"B6"
],
"carbs": "low",
"dangerous": true
}
Note that if any queried field turns out to be an array, it checks for the value inside the array, just like in the vitamins field. Let's try a bit more complex query in which we order the veggies by (a very biased) rating. Before that, you have to edit the JSON and put a rating field. I gave 4 to potato, 3.5 to carrot, and 5 to onion, then run the query with an $orderBy operation:
// Query
{"$orderBy": [{"path": "rating", "order": "asc"}]}
// Output
{
"name": "Carrot",
...
"rating": 3.5
},
{
"name": "Potato",
...
"rating": 4
},
{
"name": "Onion",
...
"rating": 5
}
There are a set of SODA drivers that allow using the same convenient QBE syntax over in Java, Python, NodeJS, etc. Here's a snippet of how the exact query would look like in Java:
try (var conn = dataSource.getConnection()) {
var soda = new OracleRDBMSClient();
var db = soda.getDatabase(conn);
var collection = db.openCollection("veggies");
var queryString = "{\"$orderBy\": [{\"path\": \"rating\", \"order\": \"asc\"}]}";
var found = collection.find().filter(queryString).getOne();
if (found != null) {
return found.getContentAsString();
}
} catch (Exception e) {
// ...
}
SQL style
Alright, that's about it from the NoSQL side. It's straightforward but not as expressive as SQL. Use the top menu to switch Database Actions into SQL mode. And immediately, you can observe how the underlying implementation of the collection works by looking at the left panel.

It's just a database table with a unique column called JSON_DOCUMENT to store JSON data. Every document added here inserts a new row to this table with metadata like an auto-generated key, creation date, last modification date, and a version identifier. Being stored in a single column makes the data inherently schema-less since you can alter the JSON however you like. AJD provides many utility functions to deal with JSON data in SQL. We'll look at a few of them here, starting with the list of all our JSON documents:
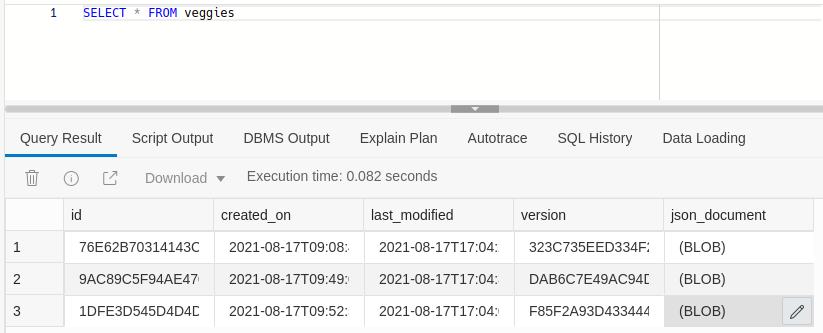
You can see how the actual JSON content isn't displayed, but you get a (BLOB) placeholder. It's because AJD stores the JSON data in a proprietary binary format called OSON, similar to how MongoDB stores in BSON. To see the textual content, we need to use the JSON_SERIALIZE function.
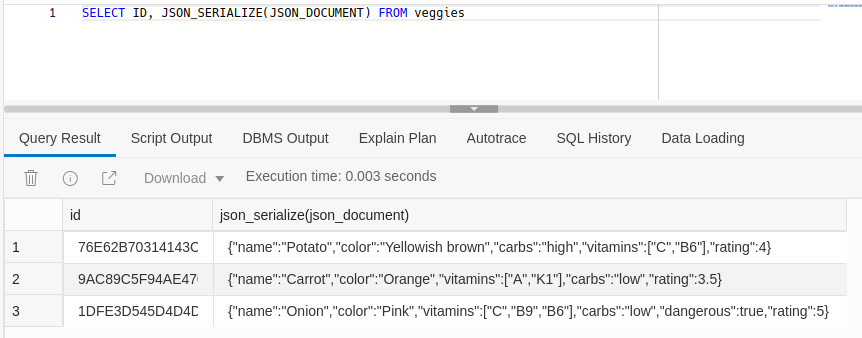
Alright, let's declare all veggies non-dangerous, except onions of course (I've seen people in tears when they try to cut it). We make use of JSON_MERGEPATCH function to merge the original JSON with a new one. Also, notice how the dot operator lets us access the inner JSON fields:
UPDATE veggies v
SET JSON_DOCUMENT = JSON_MERGEPATCH(JSON_DOCUMENT, '{"dangerous": false}')
WHERE v.JSON_DOCUMENT.name != 'Onion'

I decided to add a few more veggies now. You can use the standard INSERT clause to create documents, but that'd require filling the metadata columns manually. So we'll make use of the helper command SODA to handle this:
SODA INSERT veggies {"name":"Tomato", "color":"Red", "carbs":"low", "rating":5};
SODA INSERT veggies {"name":"Pumpkin", "color":"Orange", "carbs":"low", "rating":3};
SODA INSERT veggies {"name":"Beet", "color":"Maroon", "carbs":"high", "rating":3.5};
Now we can group veggies by their carbs and find out what their average ratings are:
SELECT v.json_document.carbs,
avg(v.json_document.rating) AS avg_rating,
count(*) AS total
FROM veggies v
GROUP BY v.json_document.carbs

The report tells low-carb veggies to have better taste than others. If you don't believe that, you should be adding more data and improving the analysis. Set up an OCI account today and test-drive Oracle AJD for your next project. Feel free to reach out in the comments, and we'll meet another day. 👋